library(tidyverse)
library(janitor)
filmpermits <- read_csv("Film_Permits.csv",
col_types = cols(EventID = col_character())) %>%
clean_names()14. Working with Dates
Video Tutorial
Dates are tricky
Dates can be annoying to work with because they come in many formats…
08/31/2023
08-31-2023
08/31/23 01:30:36
08-31-2023 12:36 PM
But R has some helpful tools that standardize dates and allow us to use them in calculations
To begin, we’re going to grab a dataset from the NYC Open Data Portal, download it as a .csv, and save it to our project.
Let’s clean it and do some summarizing
filmpermits_clean <- filmpermits %>%
select(event_type, borough, category, sub_category_name, start_date_time, end_date_time) %>%
filter(category != "WEB") %>%
mutate(type =
case_when(category == 'Documentary' ~ 'Film',
category == 'Film' ~ 'Film',
category == 'Television' ~ 'Television',
category == 'Commerical' ~ 'Commercial',
TRUE ~ 'Other')) Working with dates
We’re going to install the lubridate package and load it. Some core R packages have helpful cheatsheets like this one. With our core knowledge of how functions work we should be able to apply these to our work!.
We can use lubridate to work with dates that come in various formats. With the film permits dataset we can run the below to make R recognize these fields as dates. Here’s a lubridate cheat sheet: https://evoldyn.gitlab.io/evomics-2018/ref-sheets/R_lubridate.pdf
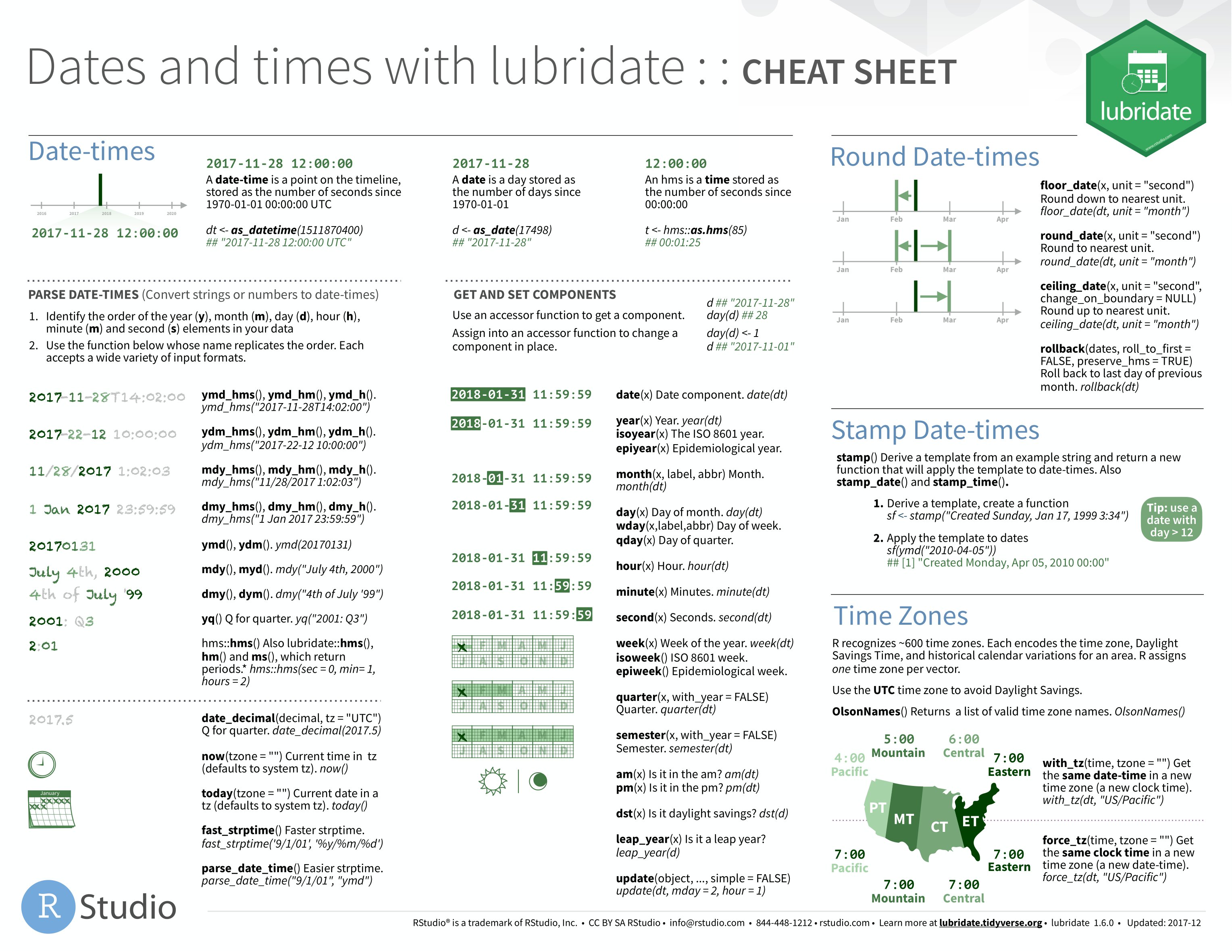

library(lubridate)
filmpermits_clean_dates <- filmpermits_clean %>%
mutate(start_date_time = mdy_hms(start_date_time),
end_date_time = mdy_hms(end_date_time))
# Let's see what the earliest start date in the dataset is. This will run in the console.
filmpermits_clean_dates %>% arrange(start_date_time)
# Let's see what the latest start date in the dataset is.
filmpermits_clean_dates %>% arrange(desc(start_date_time))Let’s use lubridate to make a list of all the film permits active just this summer. When sending R a date in a logical condition, wrap it in as.Date() so R knows its a date not a string. R & Lubridate defaults to the 'YYYY-MM-DD' format.
filmpermits_summer23 <- filmpermits_clean_dates %>%
filter(end_date_time >= as.Date('2023-06-01') & start_date_time <= as.Date('2023-08-31'))
# Now I can run the same analysis as above and see if the % breakdowns are any different.
filmpermits_summer23_grouped <- filmpermits_summer23 %>%
group_by(type) %>%
summarize(num_permits = n()) %>%
mutate(share = num_permits / sum(num_permits)) %>%
arrange(desc(share))
filmpermits_summer23_grouped